When you scale your application, you can choose from and combine two basic choices:
Scale up: Get a bigger box
Scale out: Get more boxes.
Scale Up: Get a Bigger Box
Scaling Up, is achieved by adding hardware such as Processors, RAM, and Network Interface Cards to your existing servers to support increased capacity.
This is a simple option and one that can be cost effective. It does not introduce additional maintenance and support costs.
However, any single points of failure remain, which is a Risk.
Beyond a certain threshold, adding more hardware to the existing servers may not produce the desired results.
For an application to scale up effectively, the underlying framework, runtime, and computer architecture must scale up as well.
When scaling up, consider which resources the application is bound by. If it is memory-bound or network-bound, adding CPU resources will not help.
Scale Out: Get More Boxes – Web Farm
Scaling Out, is achieved by adding More Servers and use Load Balancing and Clustering Solutions.
Scale-out scenario also protects against hardware failures. Thus less risk. If one server fails, there are additional servers in the cluster that can take over the load.
It comes with additional management cost associated with scaling out and using Web farms and clustering technology.
Scale Out – Can be achieved in both Non-Distributed or Distributed Architecture.
· In Non-Distributed, you might host multiple Web servers in a Web farm that hosts presentation and business layers. See Below figure.
· In Distributed, you might physically partition your application's business logic and use a separately Load-Balanced Middle Tier along with a Load-Balanced Front Tier hosting the presentation layer.
In Non-distributed Achitecture - Scaling out Web servers in a Web farm
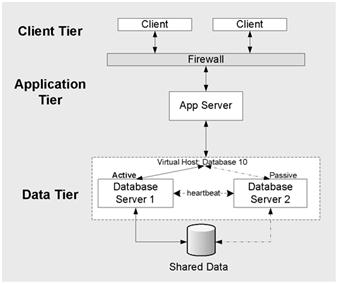
If your application is I/O-constrained and you must support an extremely large database, you might partition your database across multiple database servers. In general, the ability of an application to scale out depends more on its architecture than on underlying infrastructure.
Scaling Strategy:
1. Layered Design Practice
2. Choose between Scale-Up / Scale-Out.
3. Consider aspects like - Application Layer, Tier, Or Type of Data
4. Consider Database Partitioning at Design Time
Layered Design Practices to Follow
A Loosely Coupled, Layered design with clean, remotable interfaces is more easily Scaled Out than tightly-coupled layers with "chatty" interactions.
A Layered design will have natural clutch points, making it ideal for scaling out at the layer boundaries.
The trick is to find the right layer boundaries. For example, business logic may be more easily relocated to a loadbalanced, middle-tier Application Server Farm.
Choose between Scale-Up / Scale-Out:
As mentioned above, Scaling Out comes with additional cost. Thus one should look at Scale-Up options first and conduct performance tests to see whether scaling up meets your defined scalability and supports the necessary number of concurrent users at an acceptable level of performance.
If scaling up your solution does not provide adequate scalability because you reach CPU, I/O, or memory thresholds, you must Scale Out and introduce additional servers.
The Scaling up and then Out scenario, may not be best suitable always. You need to consider aspects of scalability that may vary by application layer, tier, or type of data.
For e.g. Scaling up and then Out, with Web or Application servers may not be the best approach. On the other hand, Scaling Up And Then Out, may be the right approach for your database servers, depending on the role of the data and how the data is used.
Consider aspects like - Application Layer, Tier, Or Type of Data:
· Stateless components: Design with Stateless components (for example, a Web front end with no In-Proc Session State and no Stateful business components), has high aspect to support Scaling Up & Out.
· Static, Reference & Read-Only data: This type of data can easily have many replicas in the right places, for better performance and scalability. This has minimal impact on design and can be largely driven by optimization considerations. Spreading replicas closer to the consumers of that data may be an equally valid approach. However, be aware that whenever you replicate, you will have a loosely synchronized system.
· Dynamic Data: This is data that is relevant to a particular user or session. And if subsequent requests can come to different Web or application servers, they all need to access it.This data is slightly more complicated to handle than static, read-only data, but you can still optimize and distribute quite easily.
The important aspect of this data is that you do not query it across partitions. For example, you ask for the contents of user A's shopping cart but do not ask to show all carts that contain a particular item.
· Core Data: This type of data is well maintained and protected. This is the main case where the "scale up, then out" approach usually applies. Generally, you do not want to hold this type of data in many places due to the complexity of keeping it synchronized. This is the classic case in which you would typically want to scale up as far as you can (ideally, remaining a single logical instance, with proper clustering), and only when this is not enough, consider partitioning and distribution scale-out.
Consider Database Partitioning at Design Time:
If your application uses a very large database and you anticipate an I/O bottleneck, ensure that you design for database partitioning up front.
Moving to a partitioned database later usually results in a significant amount of costly rework and often a complete database redesign.
Database Partitioning provides several benefits:
· The ability to restrict queries to a single partition, thereby limiting the resource usage to only a fraction of the data.
· The ability to engage multiple partitions, thereby getting more parallelism and superior performance because you can have more disks working to retrieve your data.
Hope this helps.
Regards,
Arun Manglick